一个玩得停不下来的Google神器:Ngram
你想知道某个词在16世纪以来8种语言的800多万册书中出现的频率是如何变化的吗?Google Ngram可以满足你~ 这是Google Books下的一个丧心病狂的项目。他们极其暴力地扫描了从1500年到2008年之间出版的8116746册书(据估计占人类历史上所有出版书目总数的6%),然后进行了OCR识别,建成了世界上最大的电子书数据库,然后他们又通过一系列算法从万亿级别的原始数据中识别出单个的词语和短语,构成了一个语料库(详细的方法论请看这里:
http://aclweb.org/anthology/P/P12/P12-3029.pdf)。8种语言包括英语、法语、德语、意大利语、西班牙语、俄语、希伯来语、汉语,其中英语占到大约56%。
这个语料库是完全对公众开放的。任何人都可以去Google Books Ngrams Viewer 查询任何一个或几个词在过去500年内在书籍中的出现频率变化趋势,有点像Google Trends的图书版。而专业人士或纯粹闲得蛋疼的geek们也可以下载完整的语料库自行分析:http://storage.googleapis.com/books/ngrams/books/datasetsv2.html
作为外行,Google的这个神器真是让我玩得根本停不下来~ 我来简单演示一下,把大家带入坑~
正式开始前先说明几点:
- 我不知道Google是如何选择和获取这6%的图书的,不确定是否会有系统性选择偏差,也不确定图书的幸存者偏差有多严重,所以看图得出的结论并不能随意外推。
- 语料库的内容完全来自出版图书,而不包括未出版图书或其他形式的文字,也不包括正在指数级增长的网络和电子信息。与Google Trends的高度实时性不同,图书的滞后性较长,只能在比较大的尺度上看趋势变化。
- 同一个词在不同时期的语义、用法和拼写可能会非常不同,需要谨慎解读结果。
- 我在这里选择以英语而非中文为例。一方面是因为英语的语料库最大,且英语在最近几百年来的图书中的使用率总体看来看是最广的,比较能够反映现实世界的一些变化。另一方面,汉语的字、词识别的难度很高,可能正确率不及英语,而且现代汉语和历史上不同时期的汉语的语义差异比较大,古文和现代文很多时候很难比较。不过近几十年的汉语数据应该还是不错的,我在最后也会放几个例子。
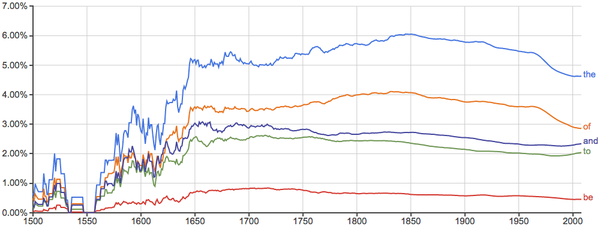
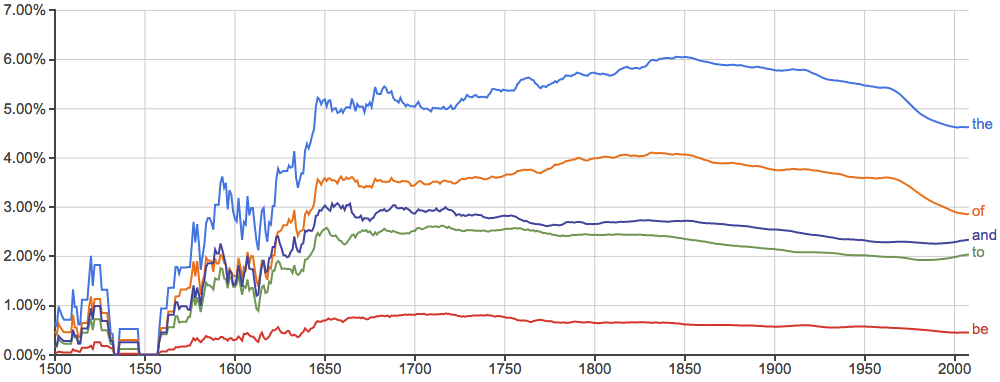
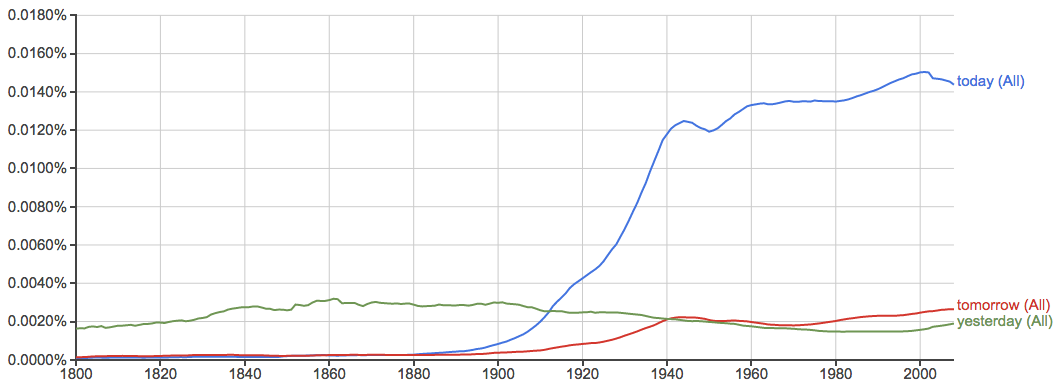
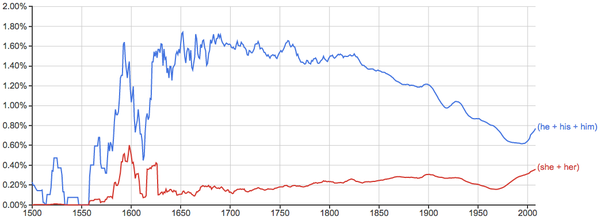
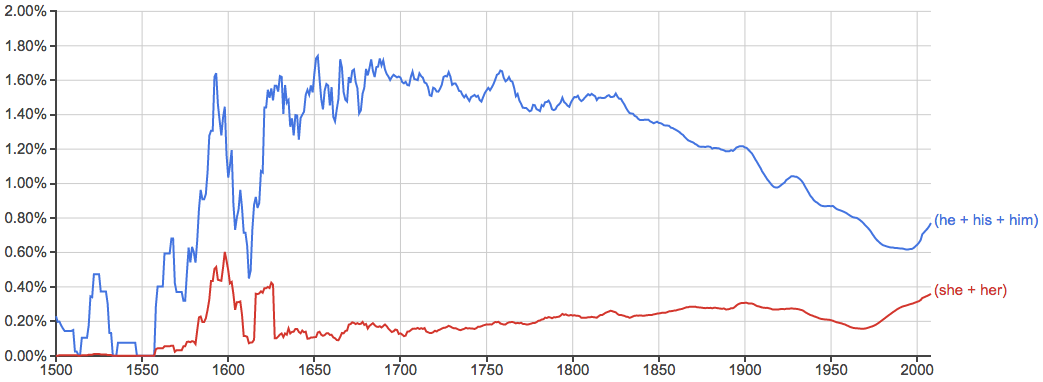
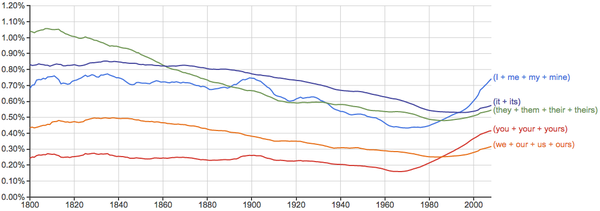
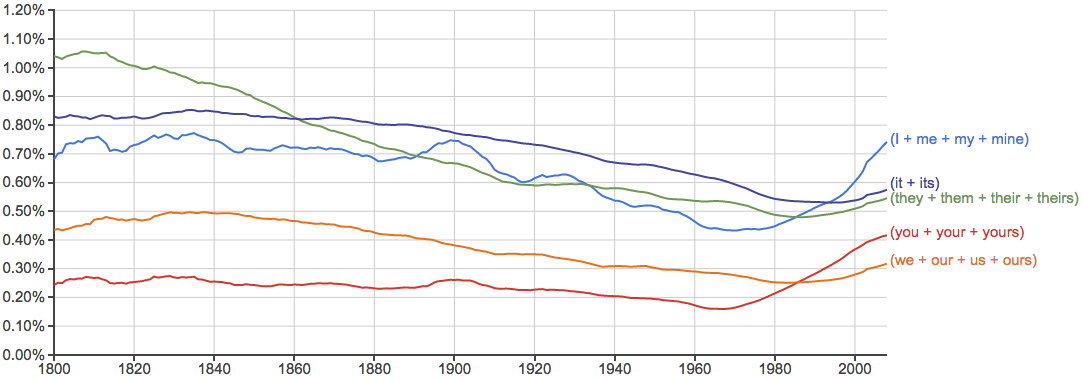
- 下面每张图里横轴是时间,纵轴是出现率,先给几个常用词做个baseline给大家感觉一下:
----------------------------------------------------------------------------------------------------
正式开始~超多图预警!
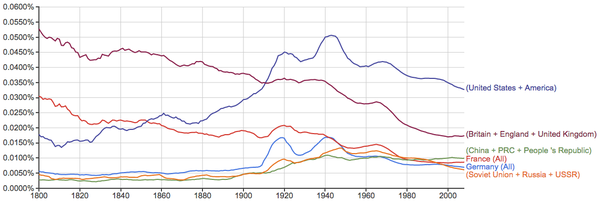
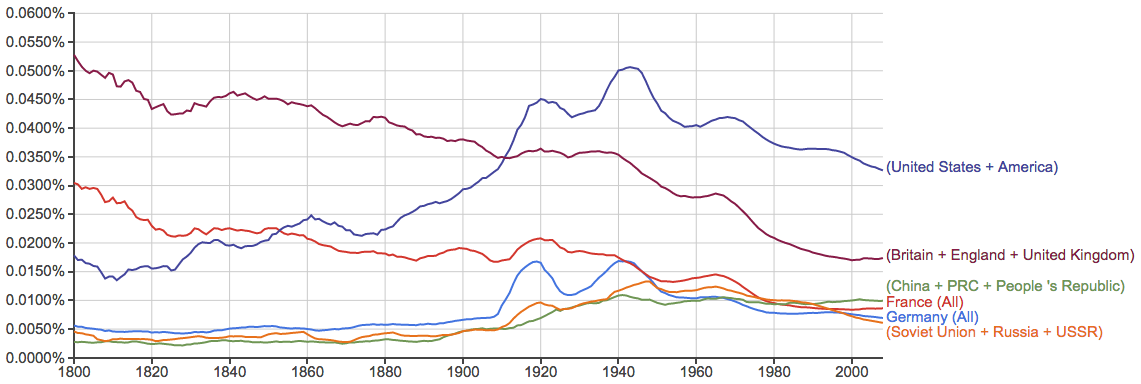
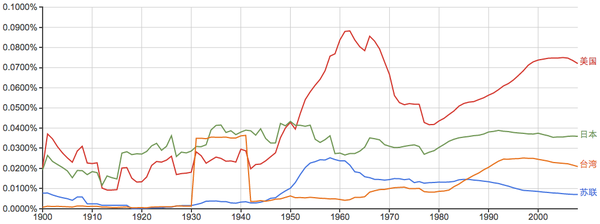
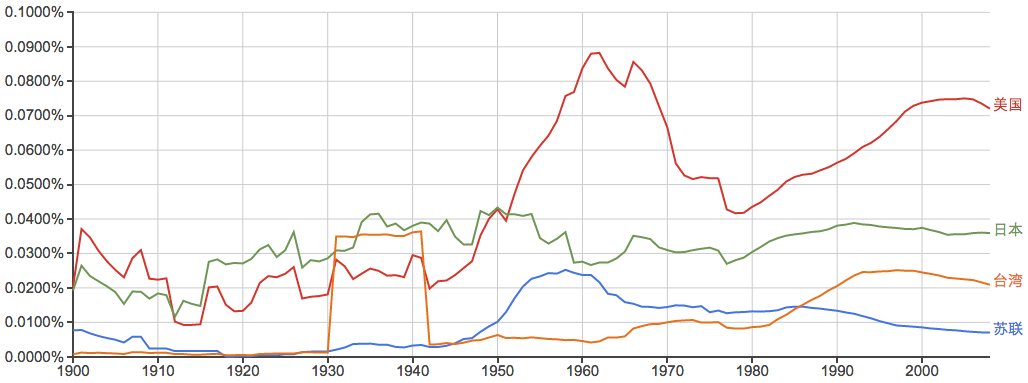
先来看看几个国家的出现率变化情况:
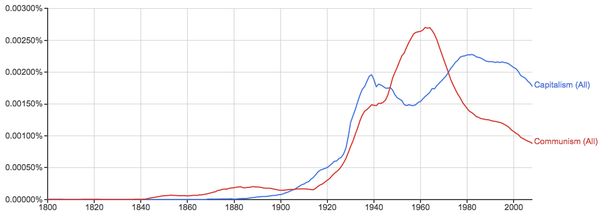
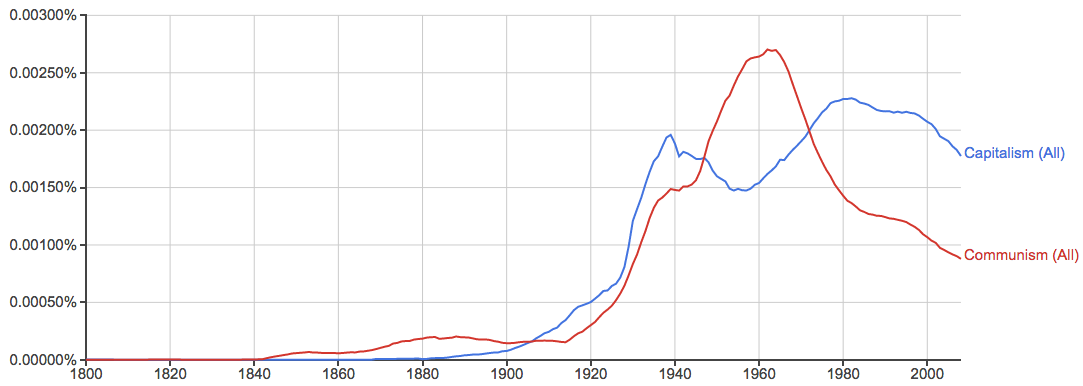
再看看资本主义和共产主义之争:
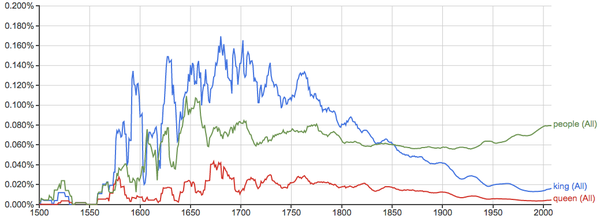
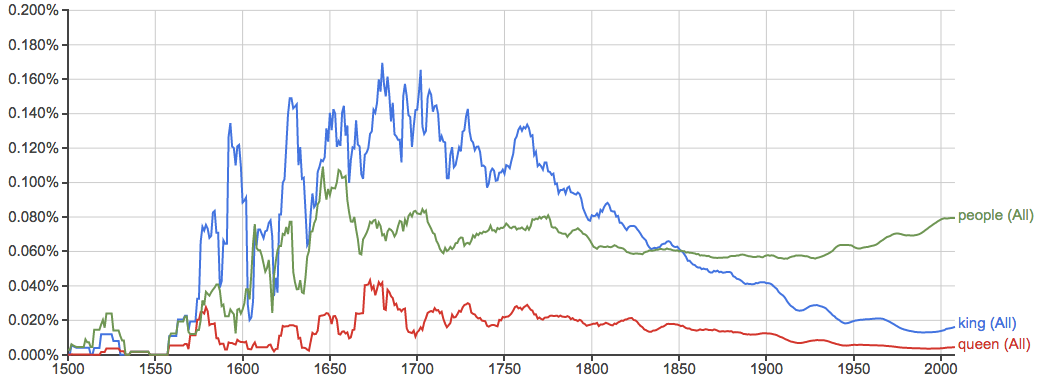
君王和人民:
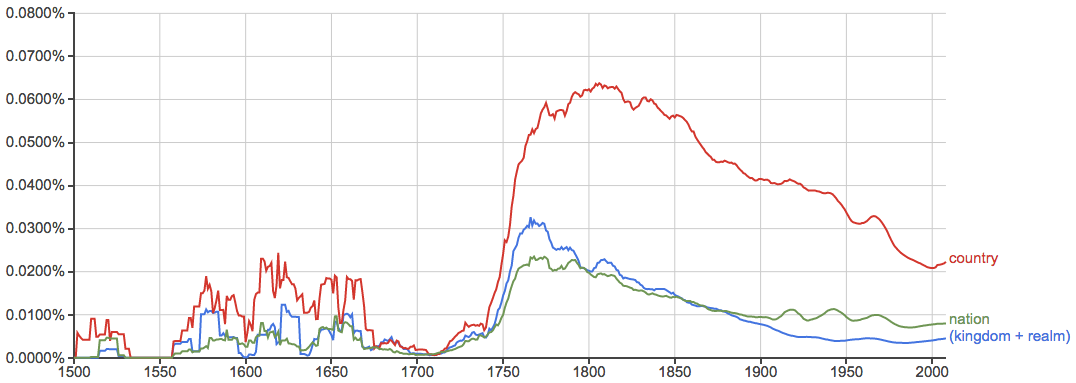
王国、国家和民族:

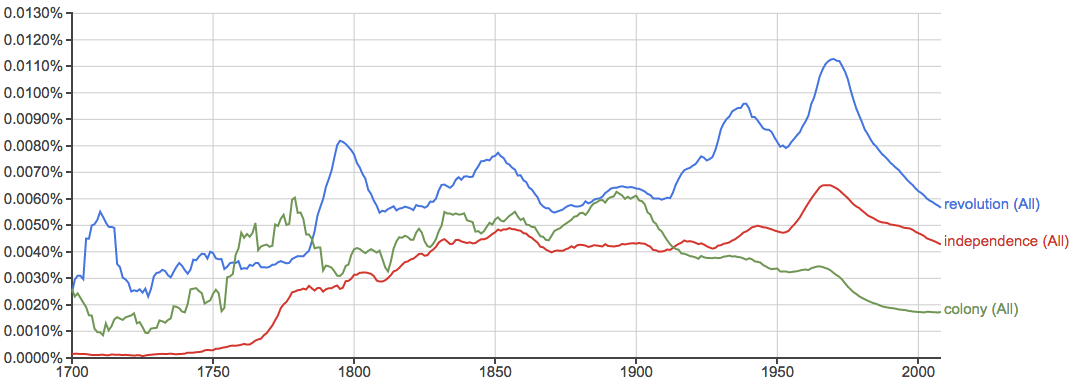
革命、独立、殖民: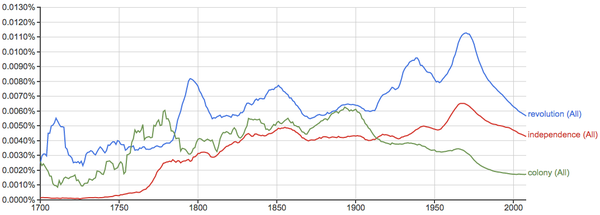
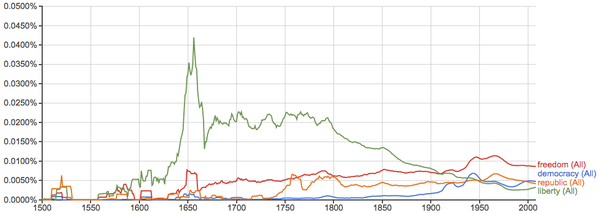
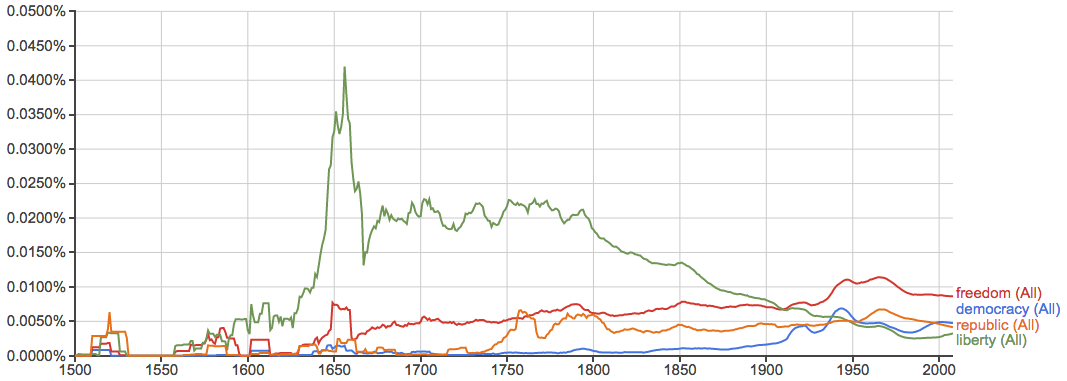
自由、民主、共和:
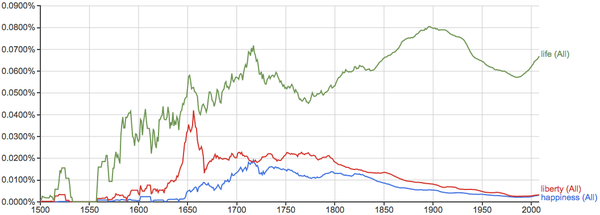
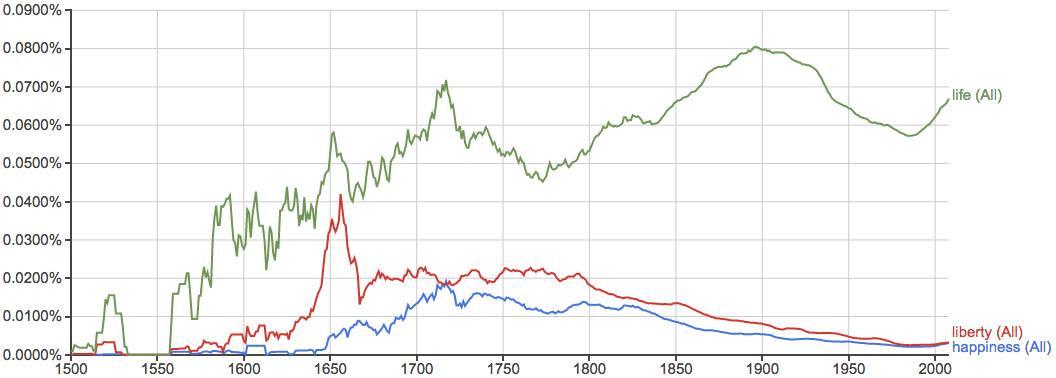
《独立宣言》里的"Life, liberty and the pursuit of happiness"
战争与和平:
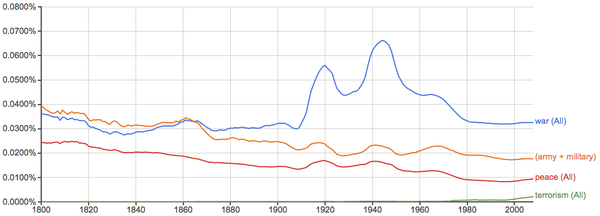
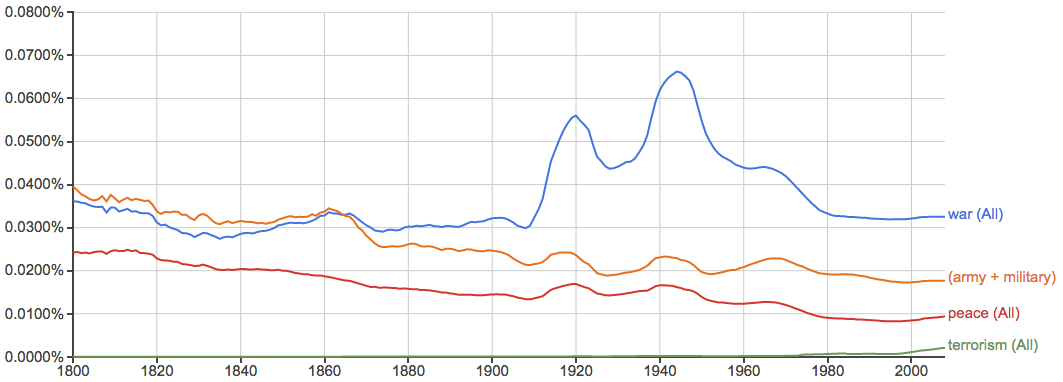
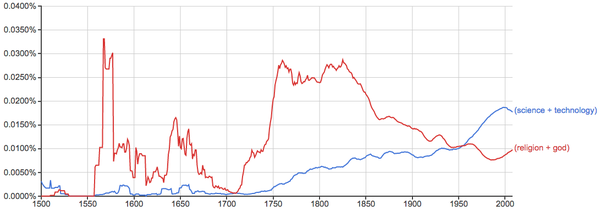
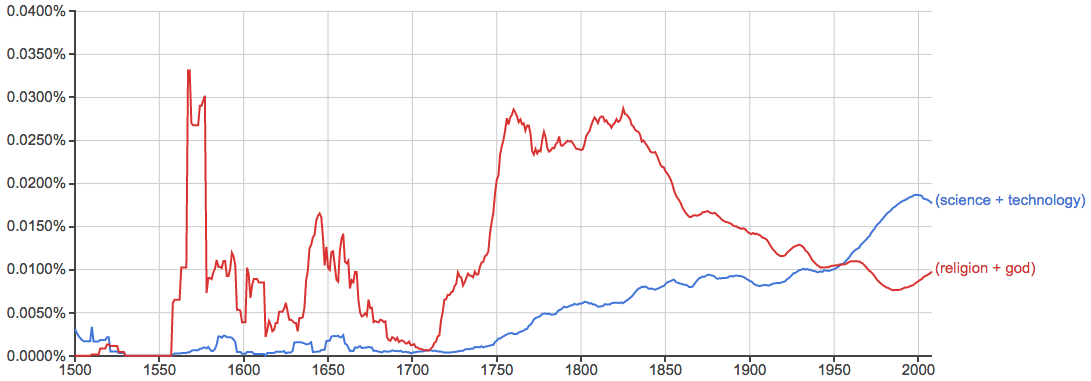
注意最近二十年的势头逆转了,但这也有可能是因为科技更多更快地转到网络等平台,而在书籍中出现得相对变少了。
计算机和互联网相关:
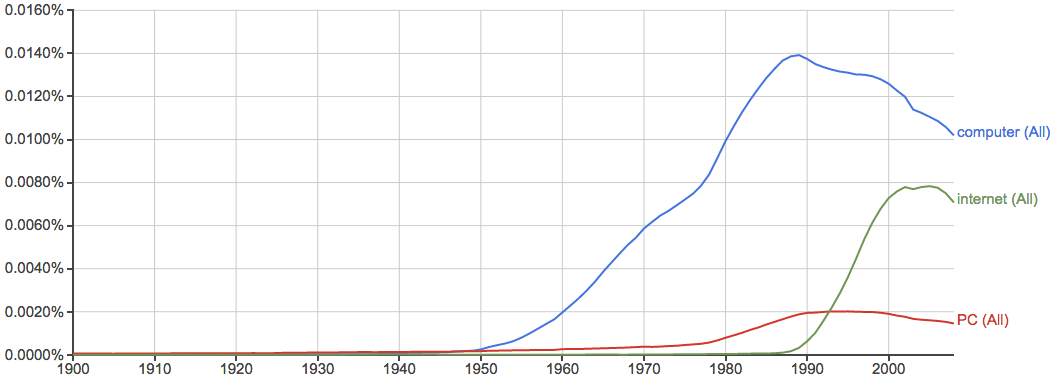
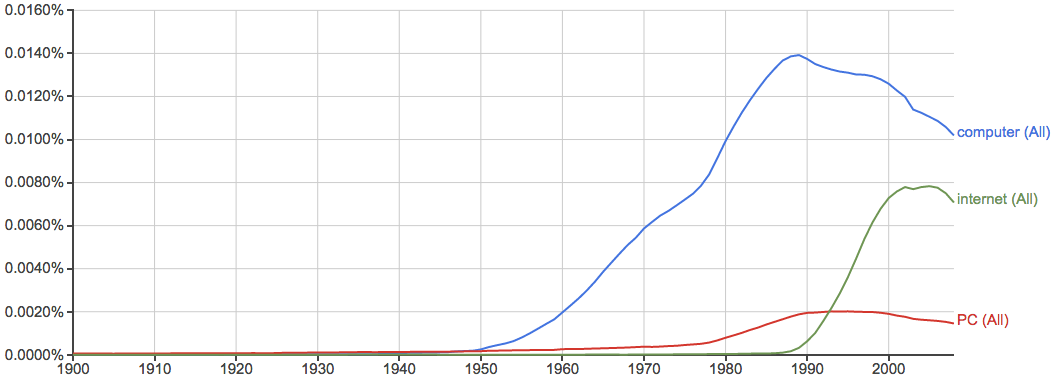

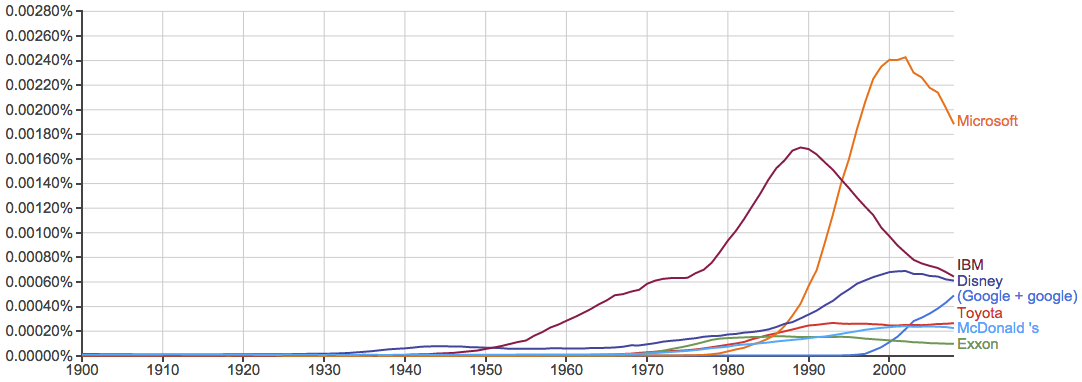
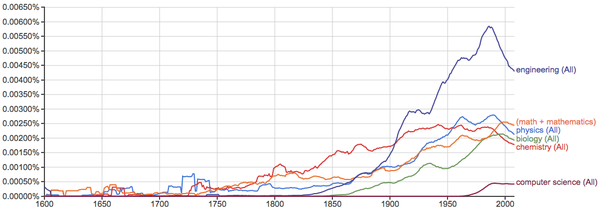
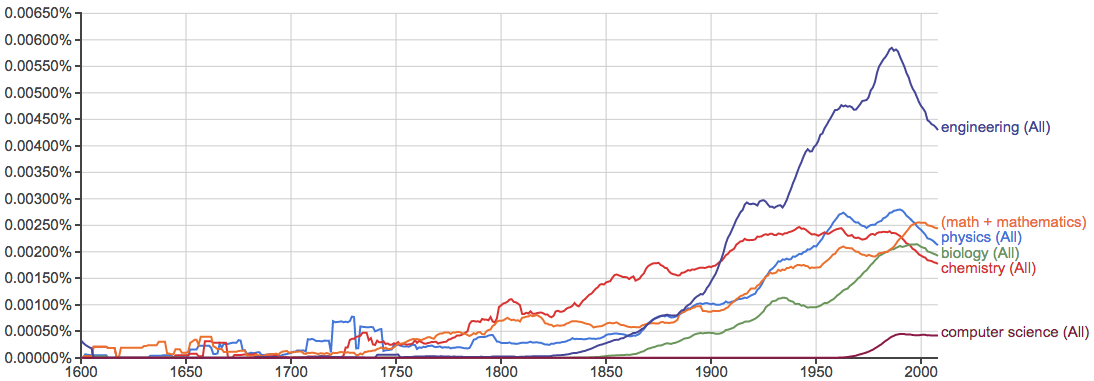
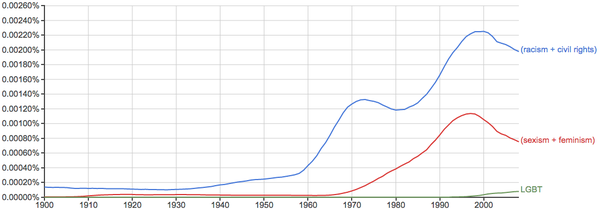
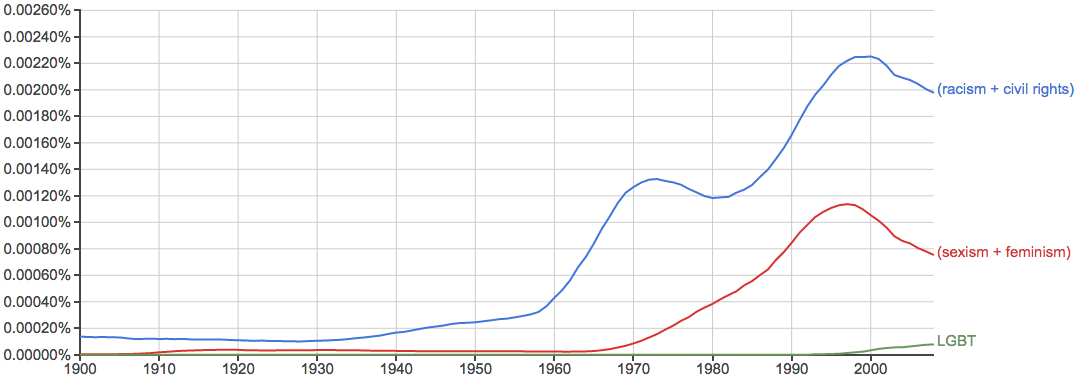
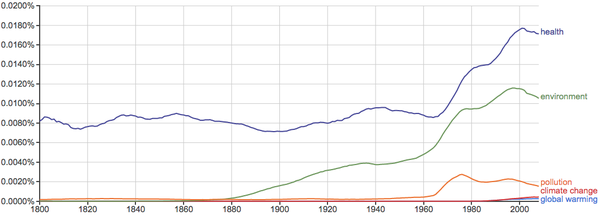
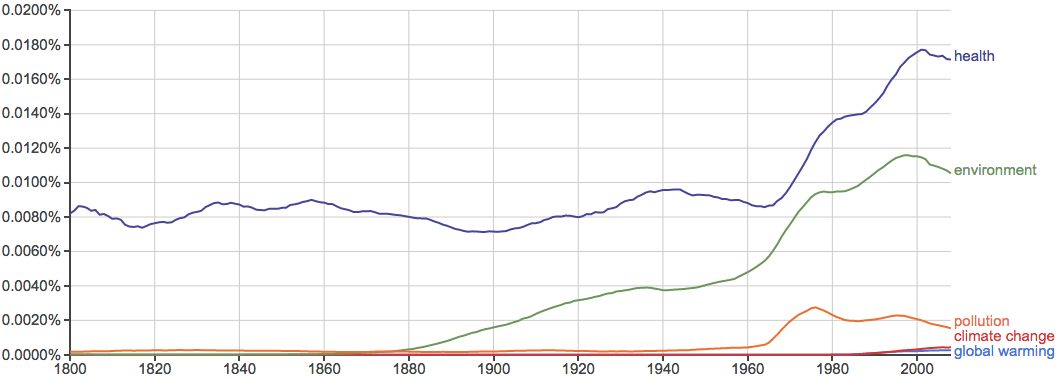
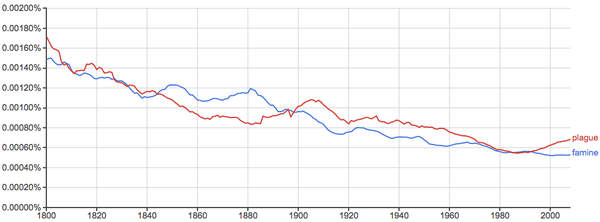
健康、环境、污染等问题的关注度越来越高:
天堂和地狱(地狱一直很坚挺啊):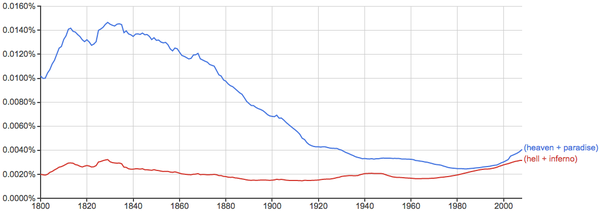
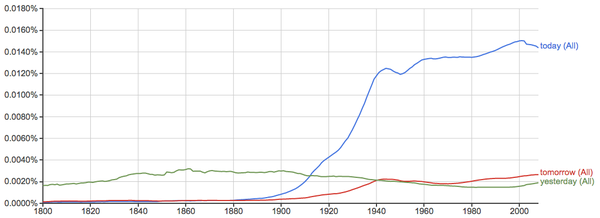
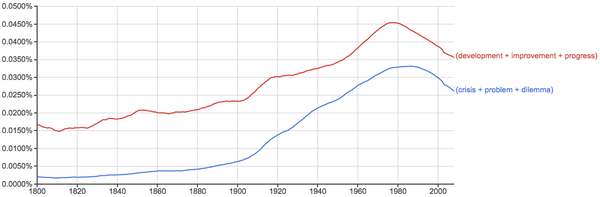
发展、进步 vs. 问题、危机
不过贫穷和不平等的出现率在上升:
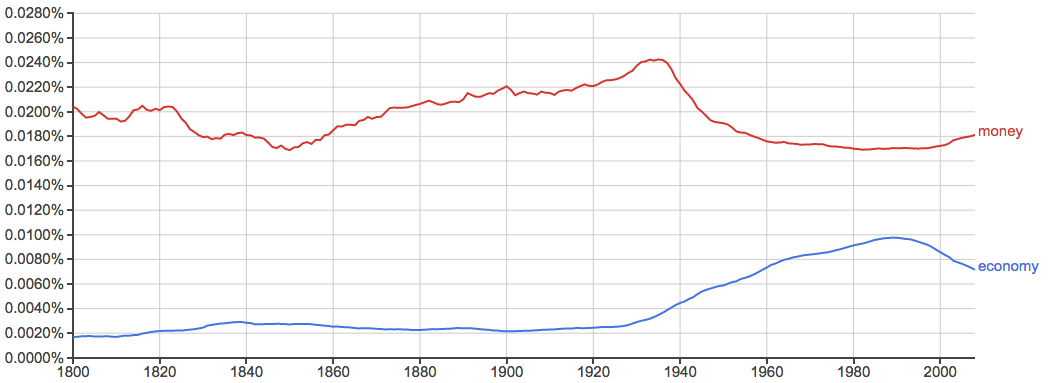
为什么从1930年左右开始money和economy的出现率是此消彼长的呢?是巧合吗?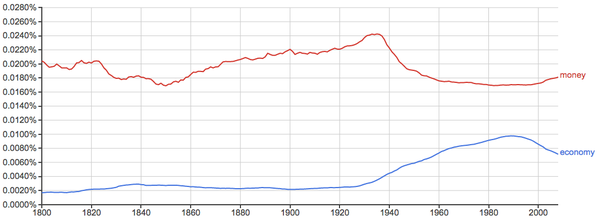
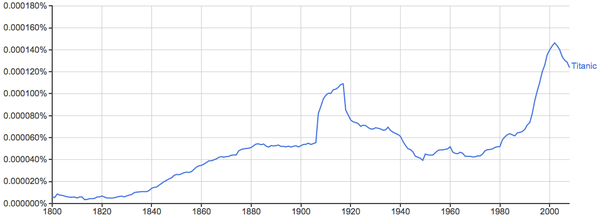
泰坦尼克:
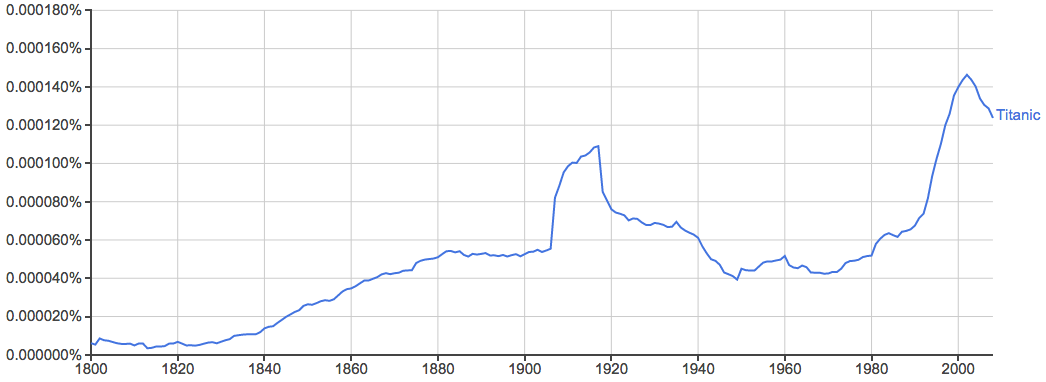
这个例子可以说明为什么一个词的出现率并不一定意味着现实世界的出现率:
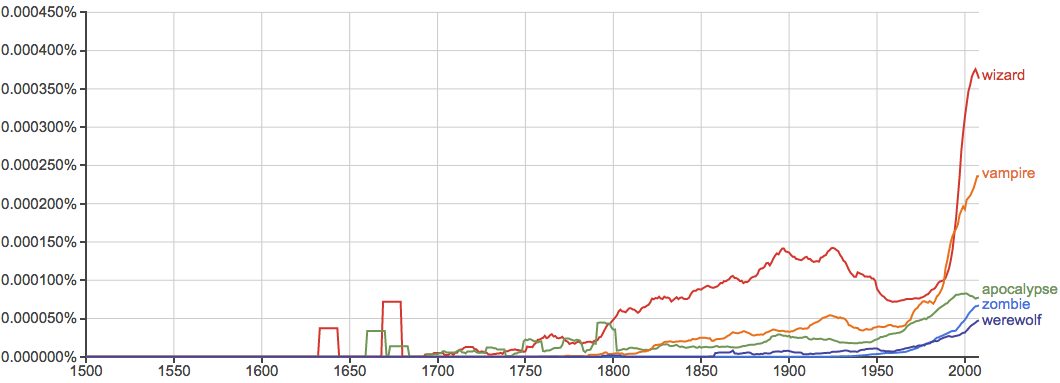
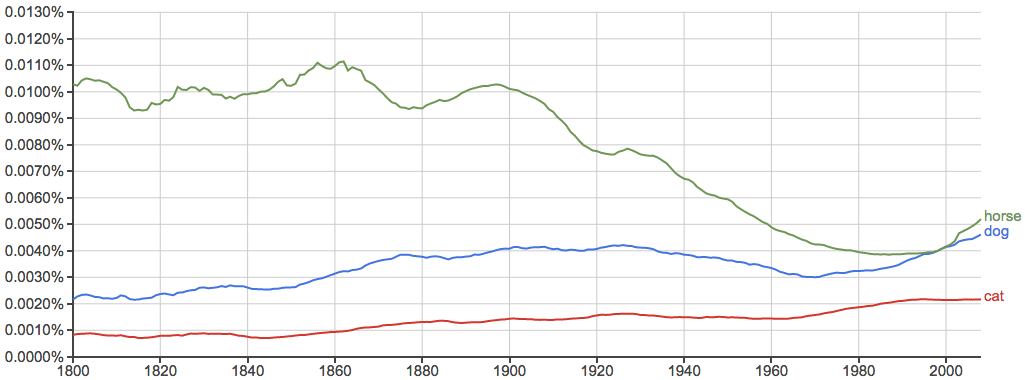
动物们:
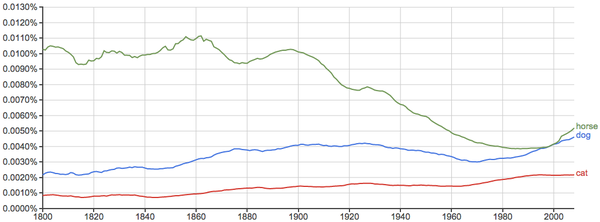
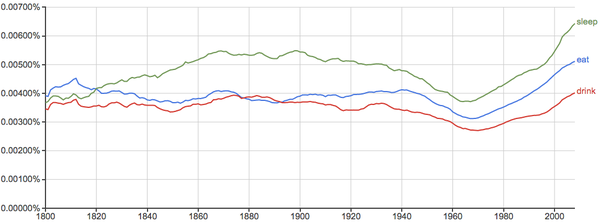
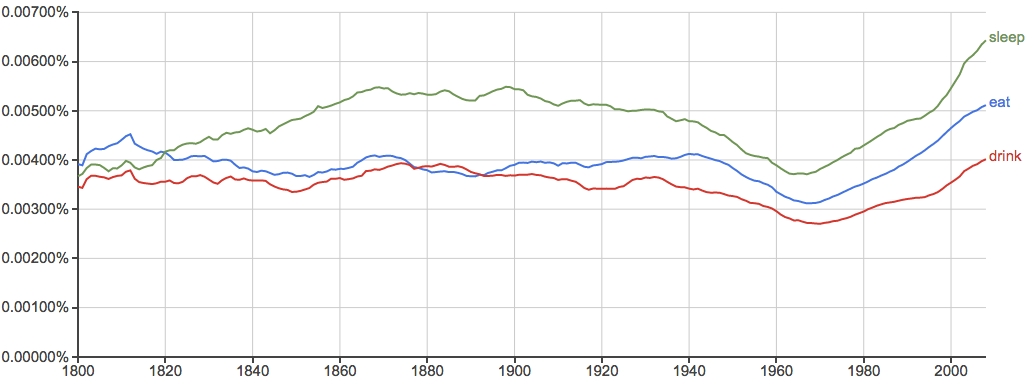
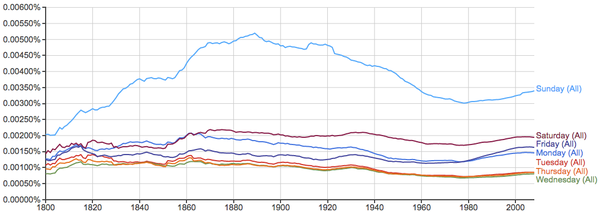
关于星期和月份的词相对比较稳定:
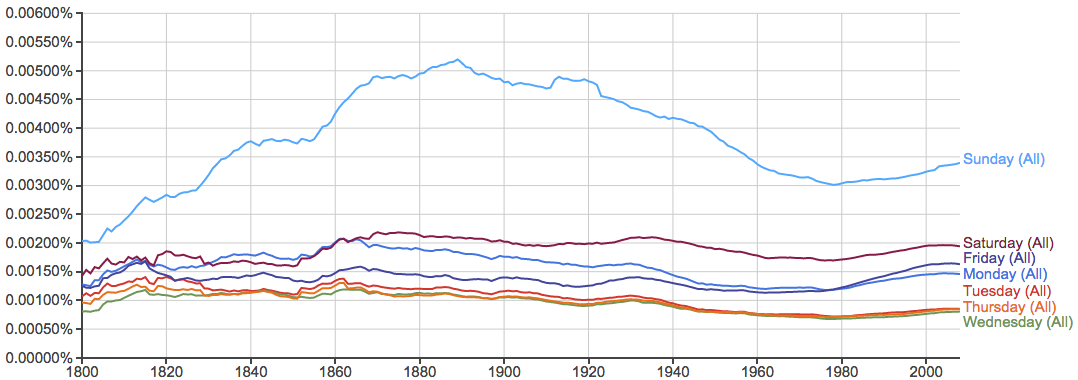
月份:
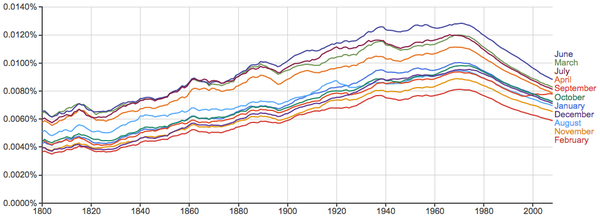
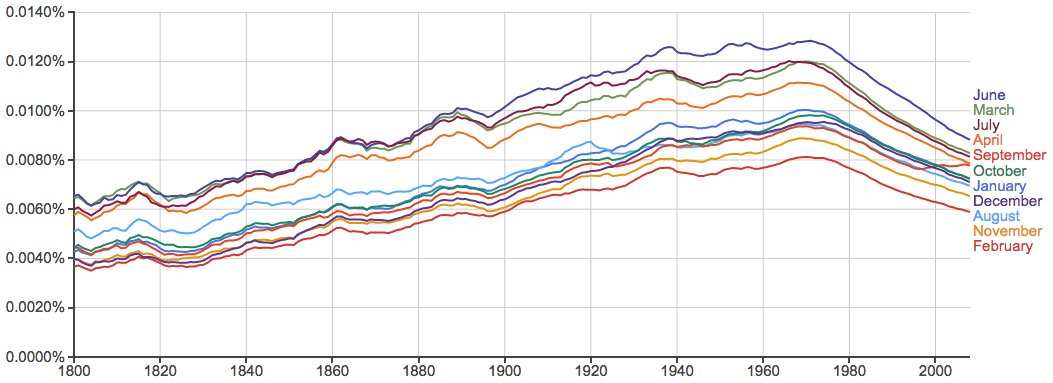
似乎气候越好的月份出现率一般也越高(May有歧义,没算进来),不过June和July都可以当人名,所以可能有些虚高。另外,近200年来这些词的整体升降趋势也很有意思,不知可以如何解释。
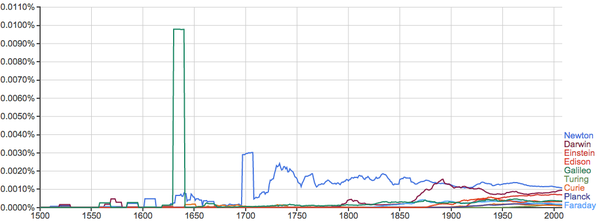
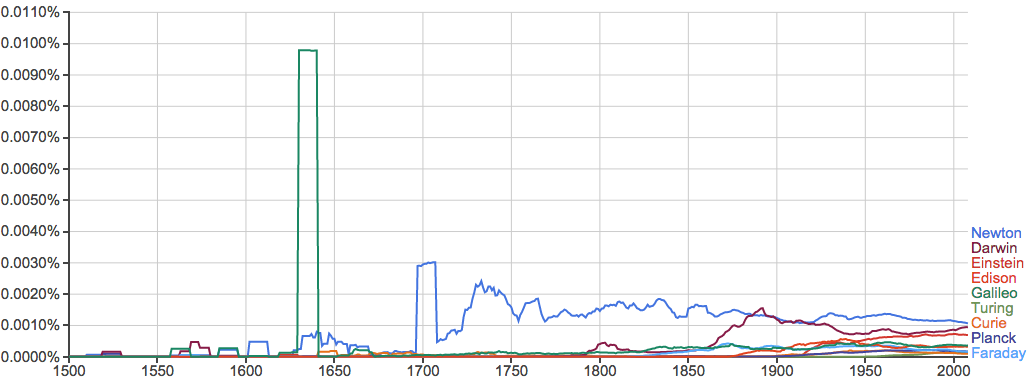
历史上的名人也很有意思。这里就举一下科学方面的例子:

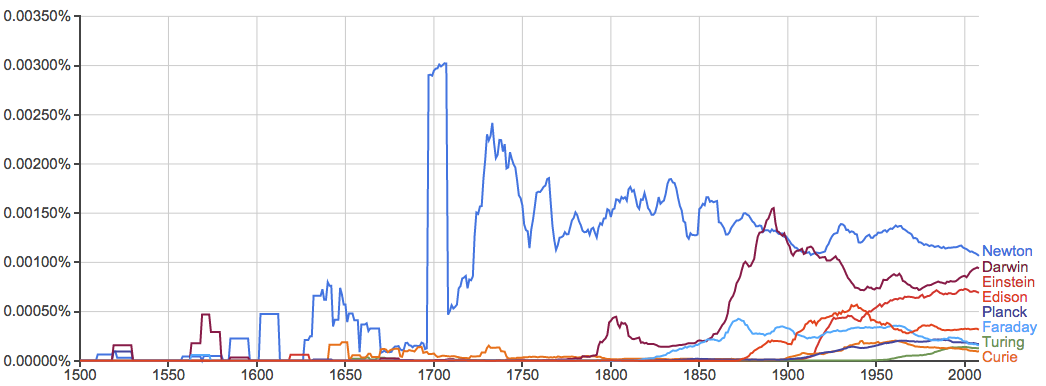
不过更夸张的是伽利略:
语言本身也有许多很有意思的变化。
比如一些已经基本不用了的英语词汇: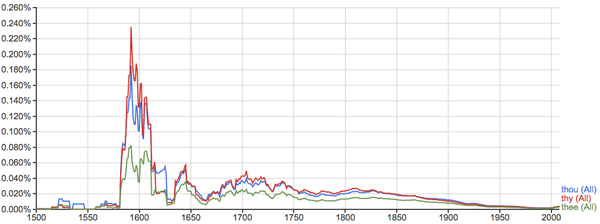
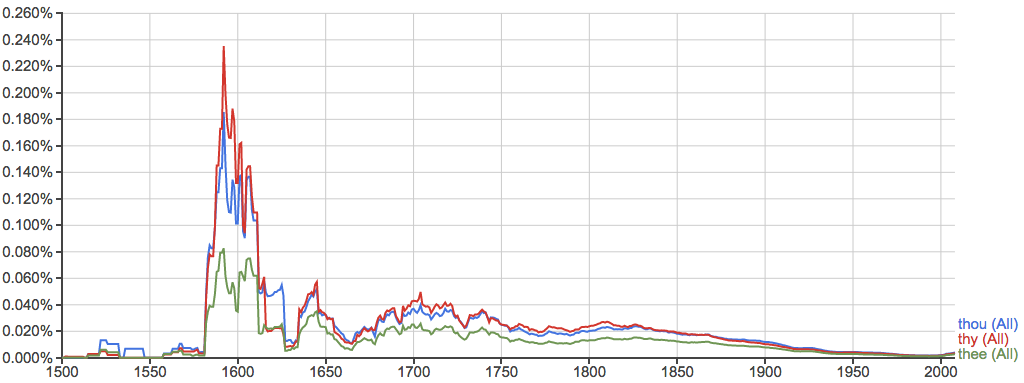
比如句首疑问词: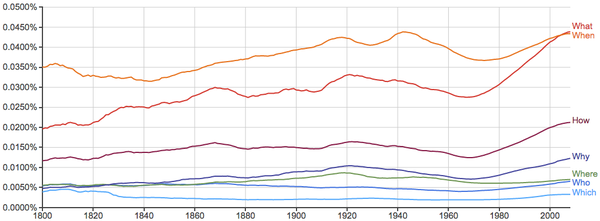
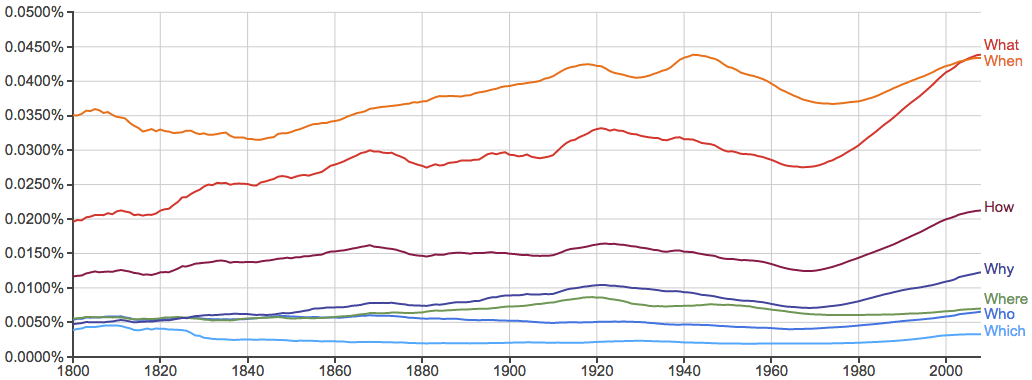
当然了,还有一些词的语义经历了巨大的变化。
最典型的例子之一就是"gay"这个词:
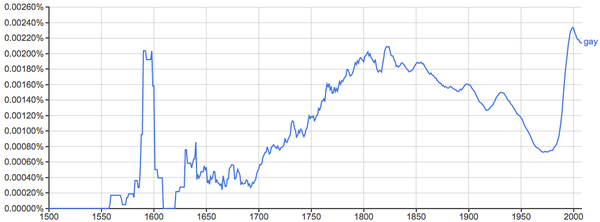
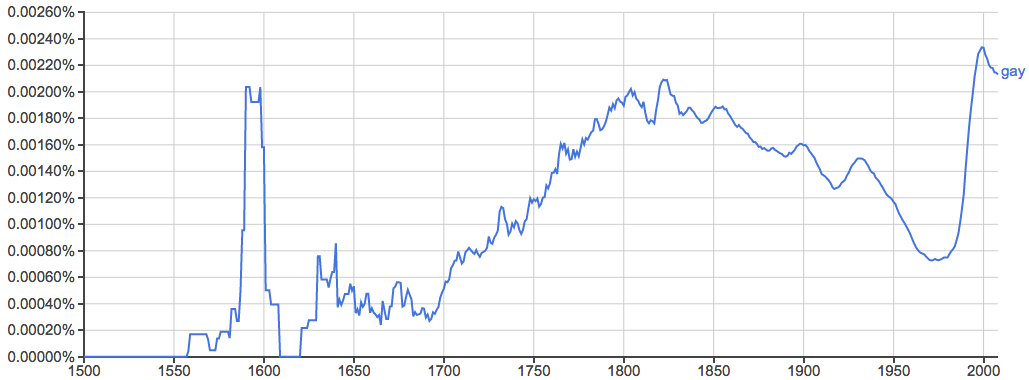
再举个很典型的例子:
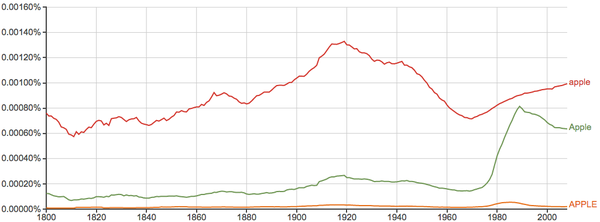
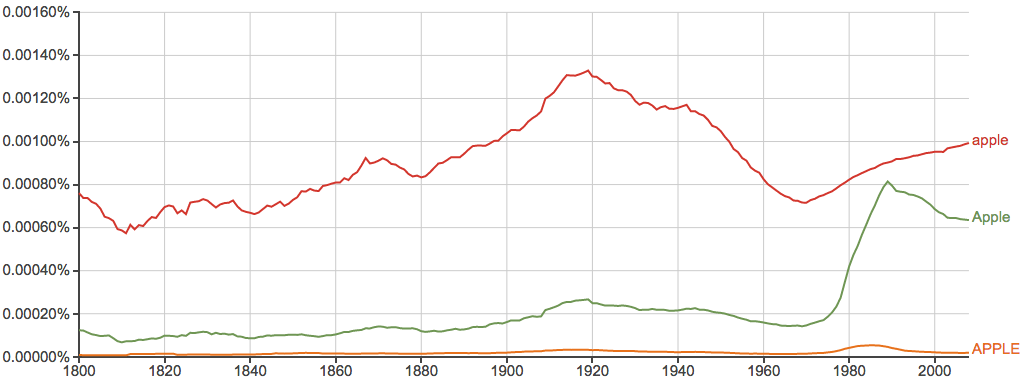
还有一个比较奇葩的案例:
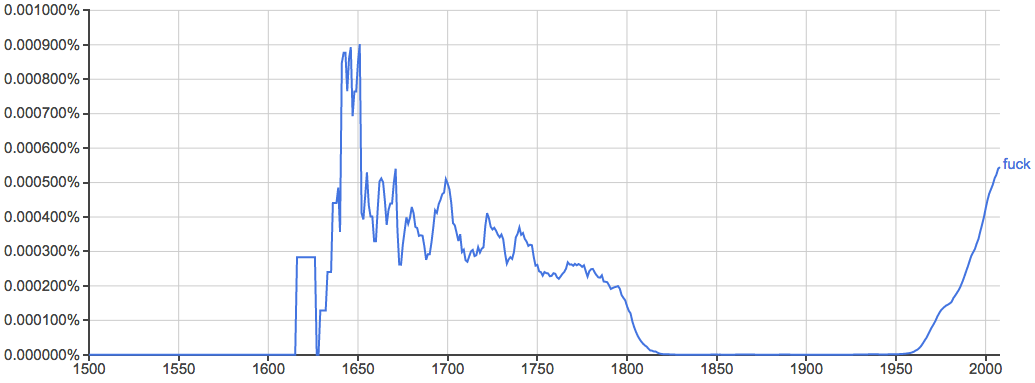
----------跑题的分界线----------
自己动手丰衣足食,我去Oxford English Dictionary查了一下fuck的词源,简直特么打开了新世界的大门啊!!没想到18世纪以前的人真的会用fuck这个词,而且fuck还就是性交的意思,但是当时似乎fuck还是个比较中性的词,可能像现在的"intercourse"之类的,没有太多低俗粗鄙的感觉。下面是历史文献中真实的“fuck”例句,有些尺度真挺大的,viewer discretion is advised:
1680 School of Venus i, in B. K. Mudge When Flesh becomes Word (2004) 10 Generally both Sexes fuck, and that so promiscuously as Incest is accounted no sin.
a1749 A. Robertson Poems (?1751) 256 But she gave Proof that she could f—k.
a1796 R. Burns
Merry Muses(1911) 71 You can f—k where'er you please.
1809
Court Martial J. N. Taylor11-12 Dec. (P.R.O.: ADM 1/5400) Mr Taylor was fucking him behind, his Yard or Penis was in the Arse of the boy.
1879
PearlOct. 127 He fucked all her toes, Her mouth, eyes, and her nose.
1865 ‘Philocomus’ Love Feast i. 9 My poor pussy , rent and sore, Dreaded yet longed for one fuck more.
1764 J. Wilkes Ess. on Woman 13 Just a few good Fucks, and then we die. (试着想象《权利的游戏》里小恶魔说这句话,简直完美)
----------回归正文的分界线----------
语料库里连数字也有,所以可以这么玩:
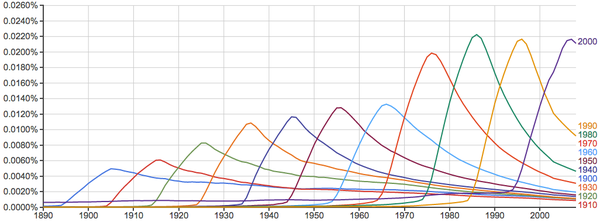
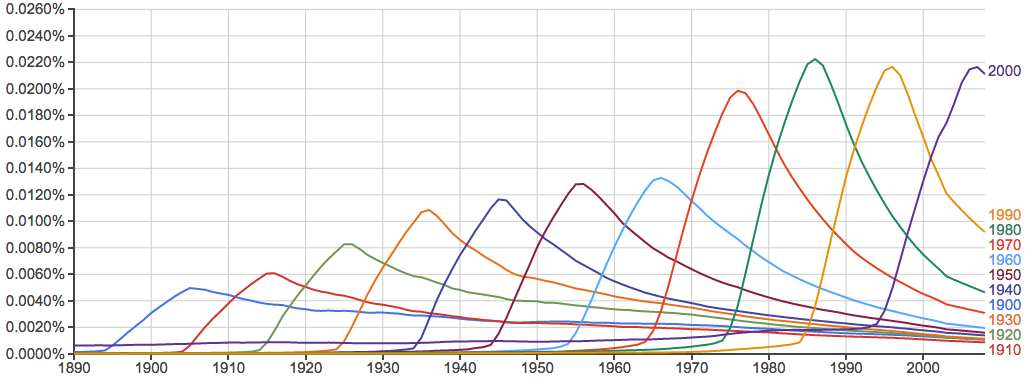
再看一下单个出现的数字:
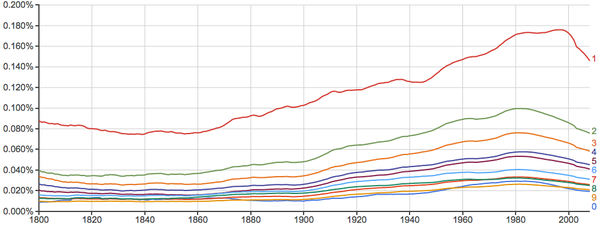
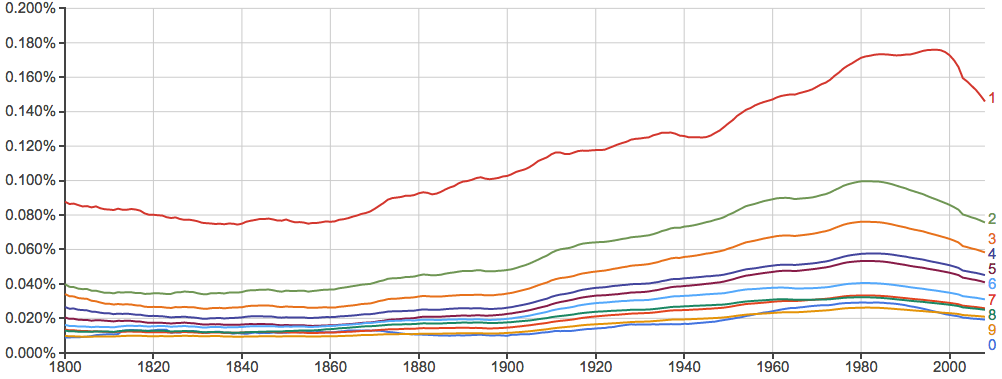
还发现一个关于圆周率的有趣的现象:
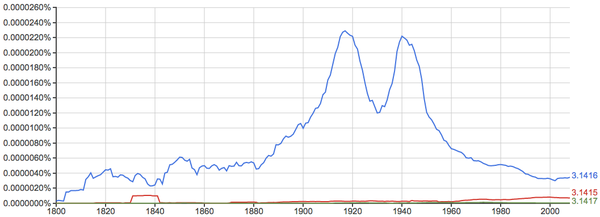
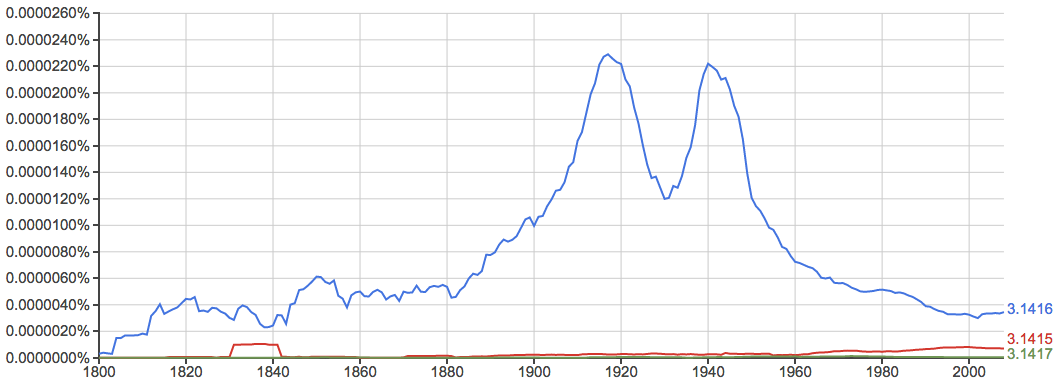
接下来看几个中文的例子。既然是中文,就搞几个有“中国特色”的吧。
非常有时代特征的一些词:
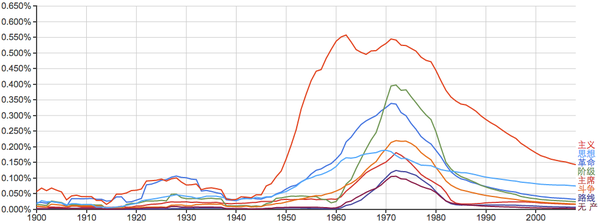
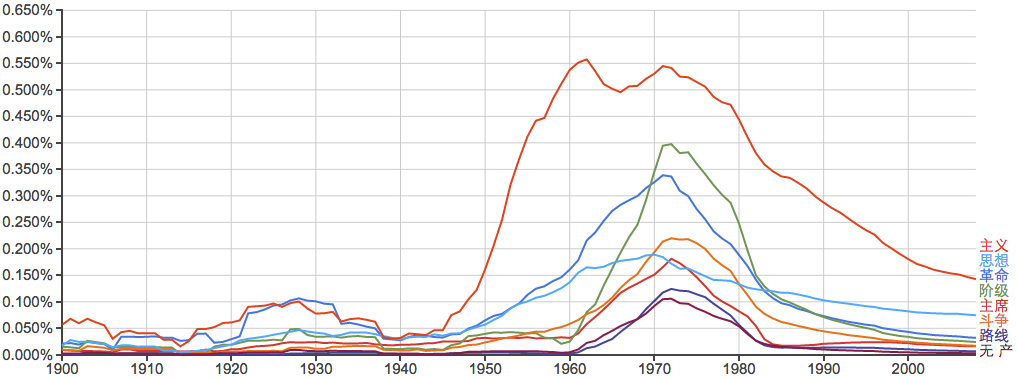
当年出版的书籍中,每50个词就有一个是这种,可见当时语言的单一和匮乏。
比较一下不同时期的重心:
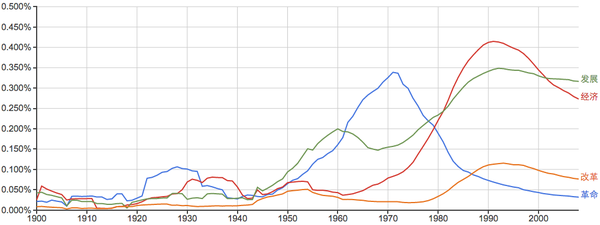
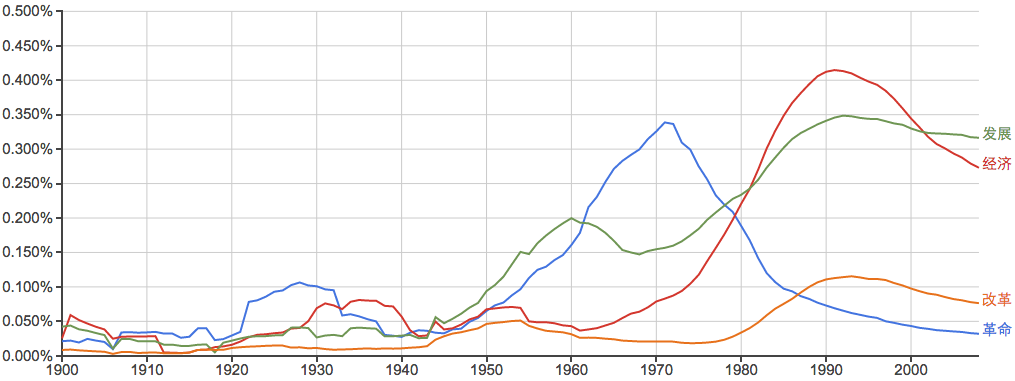
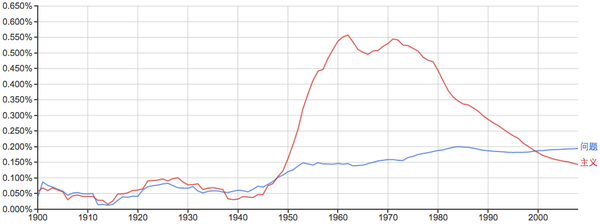
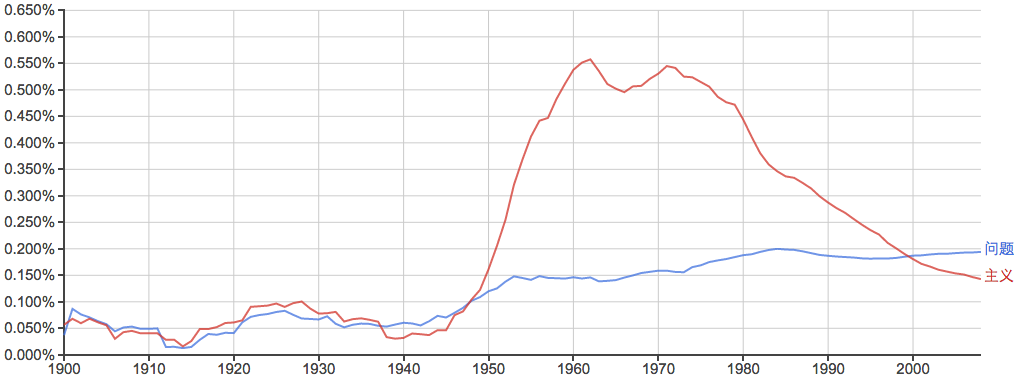
“多研究些问题,少谈些主义”:
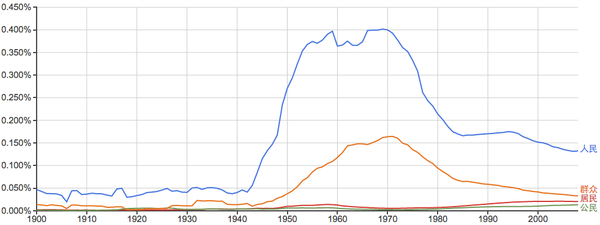
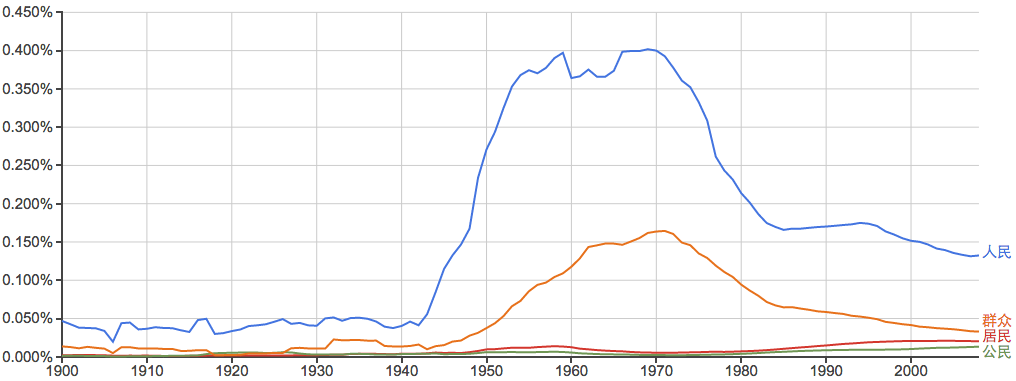
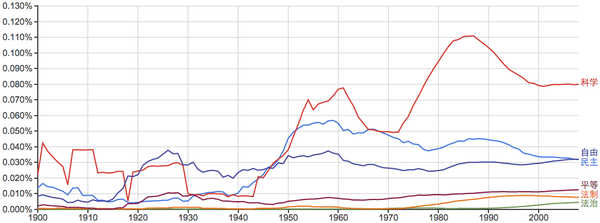
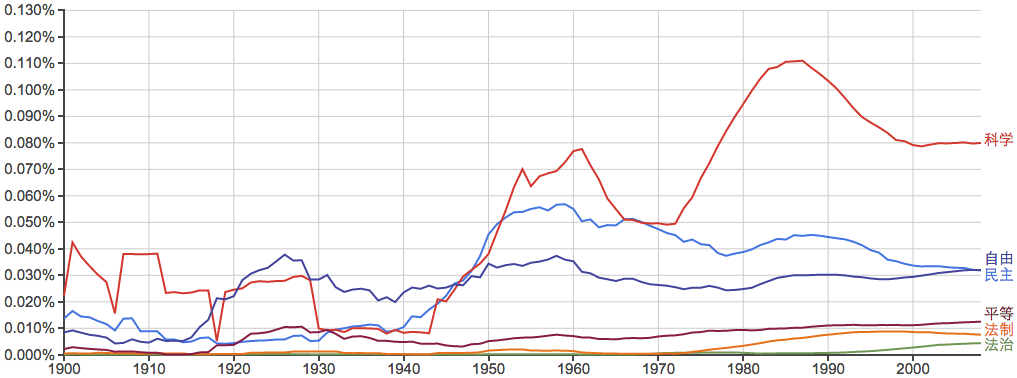
其他的一些常用词: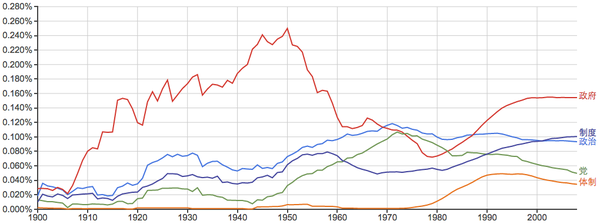
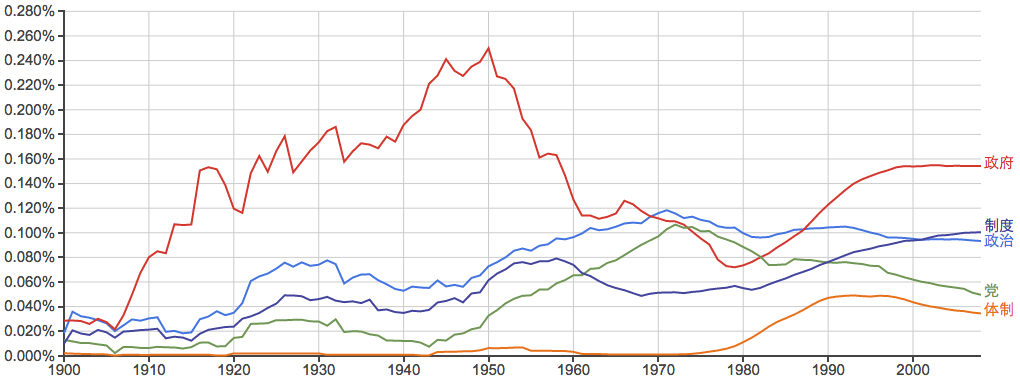
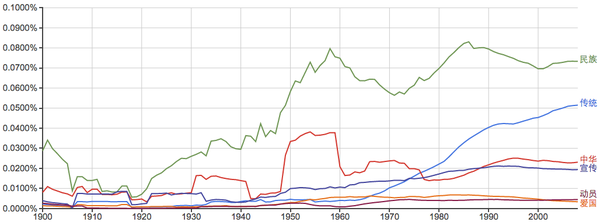
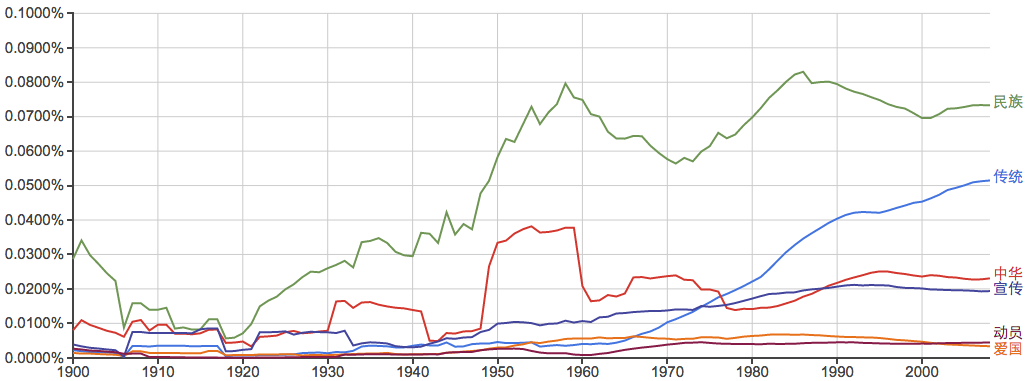
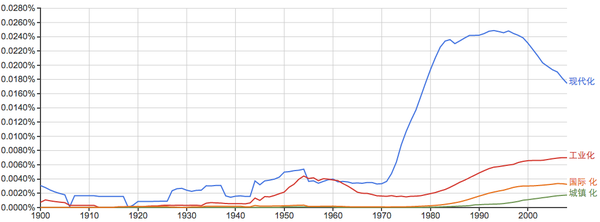
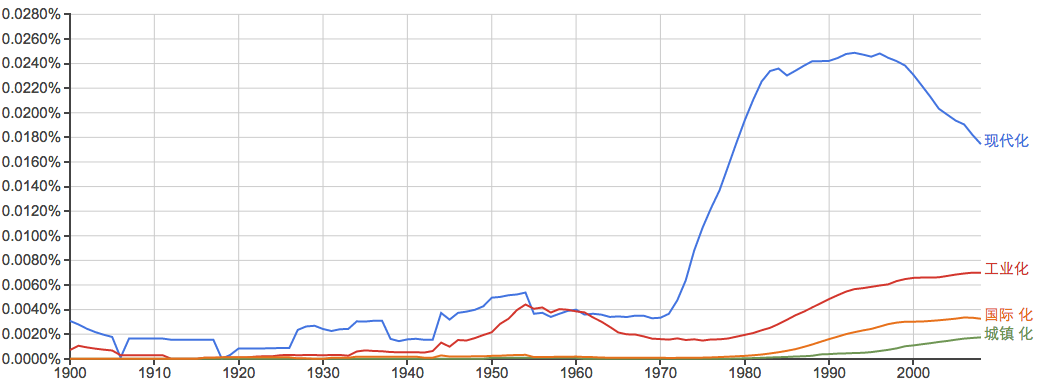
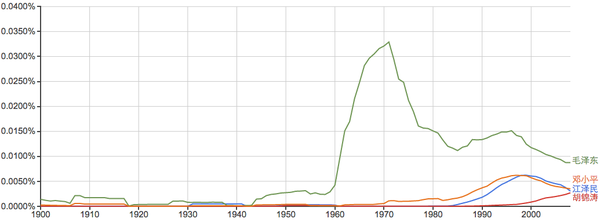
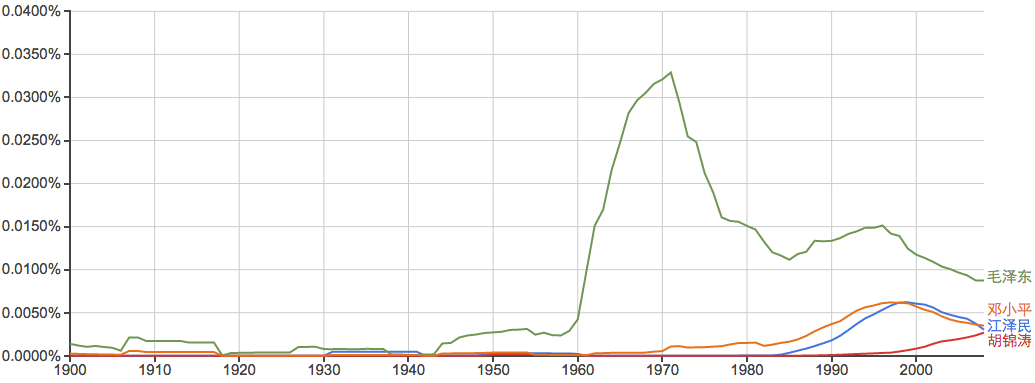
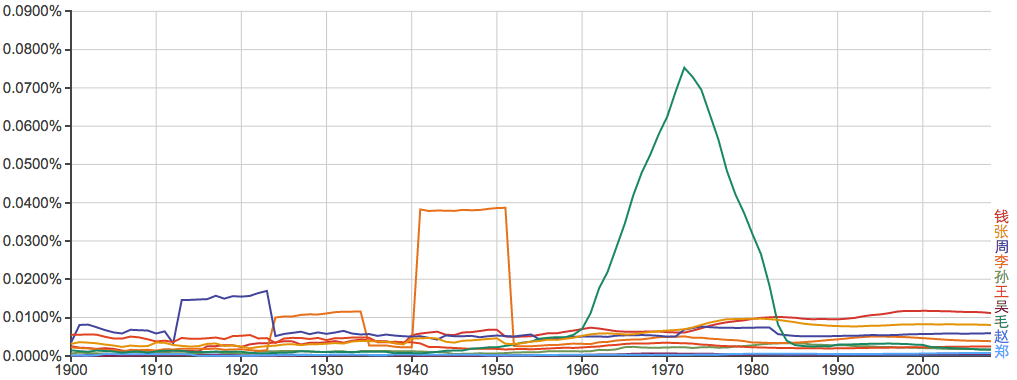
常见姓氏: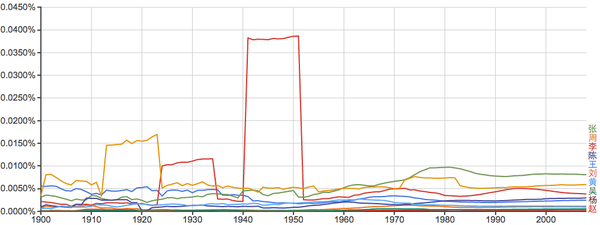
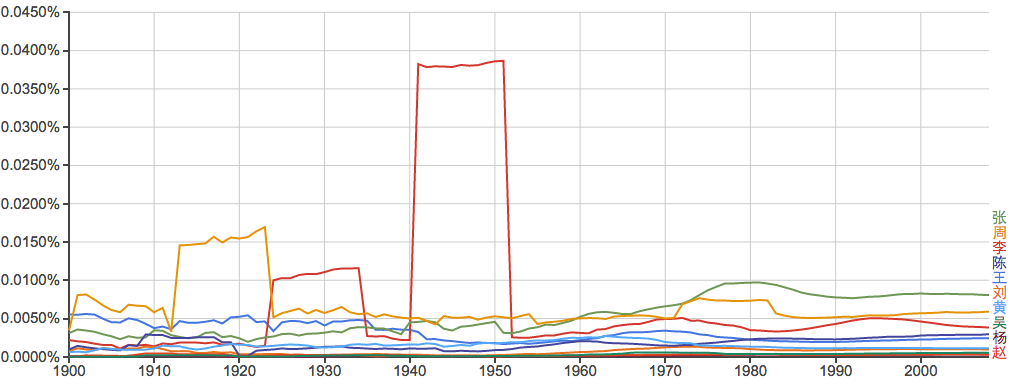
谁能告诉我40年代的“李”和20年代前后的“周”是怎么回事?...
当然了,数风流人物,还看:
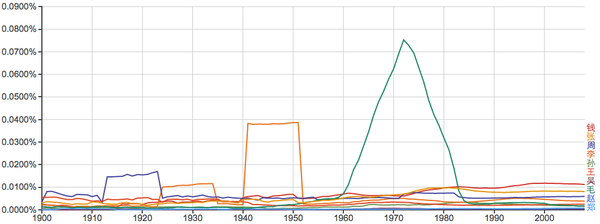
甲乙丙:
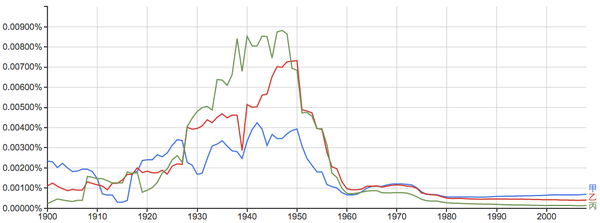
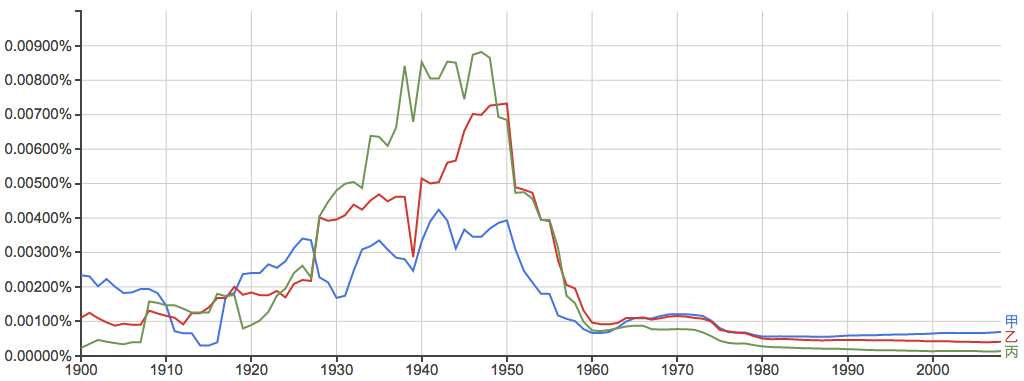
为什么在很长一段时间里甲乙丙的出现概率排序是颠倒的?
吃、喝、睡: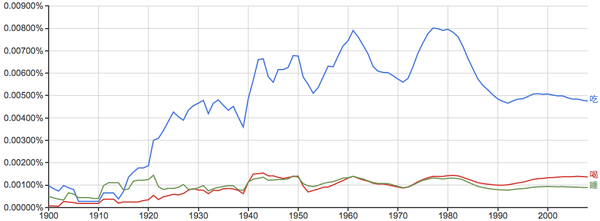
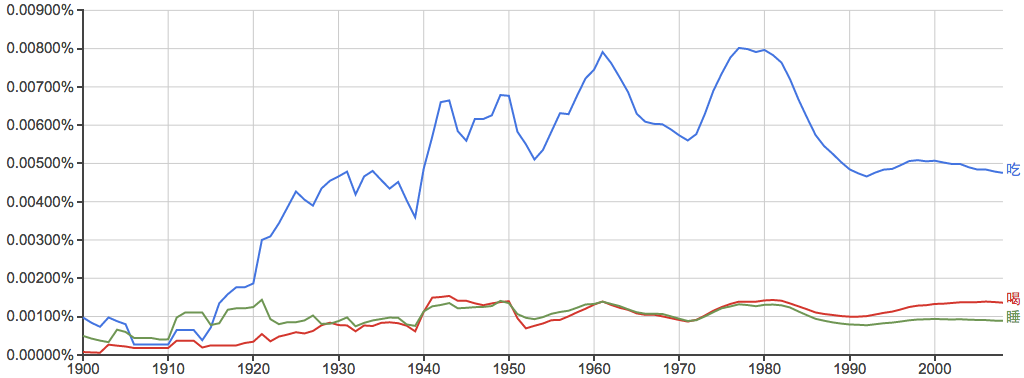
其实“吃”在中文书里出现的频率和"eat"在英文书里出现频率差不多,但是中文里“吃”相对于“喝”、“睡”明显要重要得多...
英语 vs. 汉语:
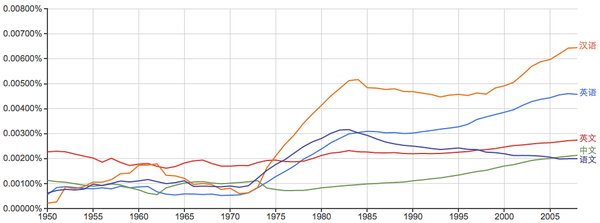
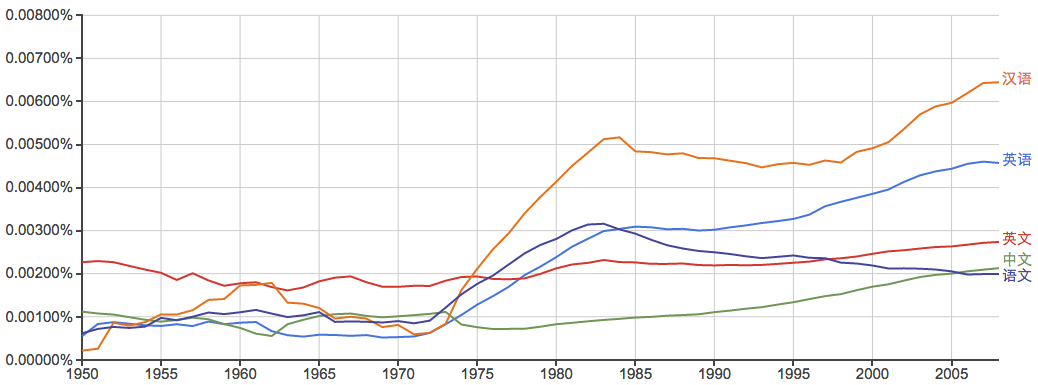
东南西北:
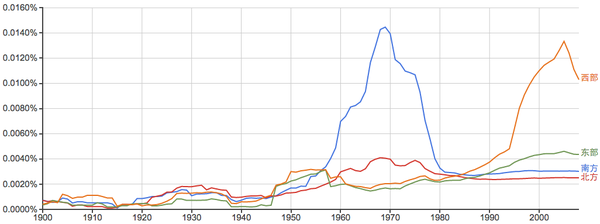
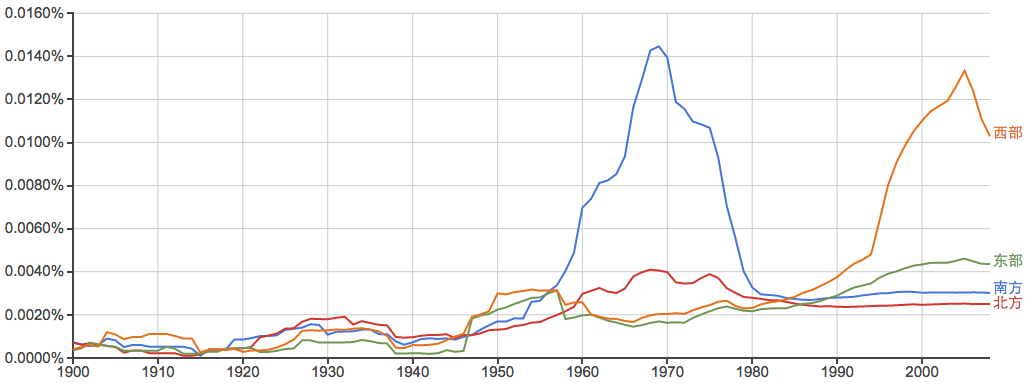
---------------------------------------------------------------------------------------------------
再下去又要停不下来了,就先写到这儿吧~总之这东西有太多的玩法,特别适合kill time~ 大家如果想到或发现什么特别好玩的词也可以写在评论里。
对了,Ngram的搜索中还有各种高级玩法,最基本的比如+,-,*,/等逻辑运算,还能用*进行模糊搜索,还能specify某个词的词性(名词、形容词、动词...)和在句子中的位置(句首、句尾),还能对词形变化(booked,books,booking之类的)进行模糊搜索,还能用:进行跨语言比较,甚至能算两个词之间的dependency……简直黑科技!我怎么现在才知道?!具体请看:https://books.google.com/ngrams/info#
